타이타닉 데이터 셋으로 생존자를 예측하여 캐글 경진대회를 입문해보고자 한다.
순서는 EDA - Feature Engineering - Modeling으로 진행된다.
cf. 캐글 경진대회란?
👉 Kaggle이 궁금해? Kaggle의 모든 것! : 네이버 블로그 (naver.com)
타이타닉 데이터 셋
데이터 셋에는 승객의 정보, 생존에 대한 정보가 들어있다.
승객의 정보를 토대로 해당 승객이 생존했는지를 예측하는 것이 목표이다.
주어진 데이터셋은 아래와 같다.
# 상위 5개의 row 조회
train.head()| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
- Survived : 0 = 사망, 1 = 생존
- pclass : Ticket class 1 = 1st, 2 = 2nd, 3 = 3rd
- sibsp : (siblings + spouses) 형제나 배우자
- parch : (parents + children) 부모나 자식
- ticket : Ticket number
- fare : 요금
- cabin : 객실 번호
- embarked : 선착장 정보 C = Cherbourg, Q = Queenstown, S = Southampton
이미 알려진 타이타닉의 정보를 토대로 아래의 내용을 유추할 수 있다.
- 아래부터 가라앉았으므로 3등석보다 1등석의 생존 확률이 높음
- 여성과 아이들의 생존 확률이 높음
Data Formation
1. shape
train.shape(418, 11)test.shape(891, 12)train 세트에는 891명의 승객 정보가 있고, 12개의 column이 있다.
test 세트에는 418명의 승객 정보가 있고, 11개의 column이 있다.
train 세트와 비교했을 때, test 세트의 column이 하나 부족하다.
=> 예측해야할 데이터인 Survived column은 test에 없기 때문!
2. isnull()
pandas에서 제공하는 isnull() 함수로 결측치를 확인할 수 있다.
결측치는 평균값을 대입하거나 데이터 자체를 삭제하는 등의 방법으로 Feature Engineering 단계에서 보정해야 한다.
train.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
test.isnull().sum()PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64👉 Age, Cabin, Fare의 정보가 부족함을 알 수 있다.
Visualization
bar chart (막대그래프)를 이용해 각 피쳐에 대한 생존, 사망을 시각화하자.
# 변수로 집어넣은 feature에 대해 bar chart를 그리는 함수
def bar_chart(feature):
survived = train[train['Survived']==1][feature].value_counts()
dead = train[train['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived,dead])
df.index = ['Survived','Dead']
df.plot(kind='bar',stacked=True, figsize=(10,5))
bar_chart('Sex')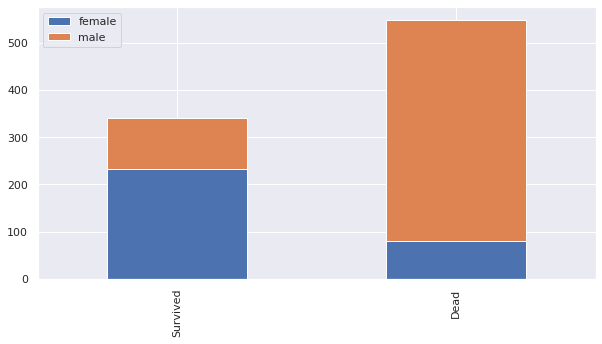
bar_chart('Pclass')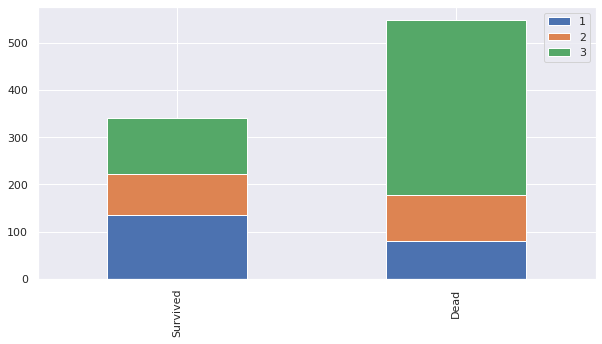
bar_chart('SibSp')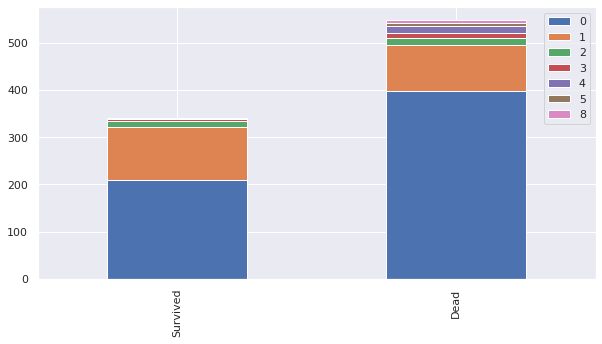
bar_chart('Parch')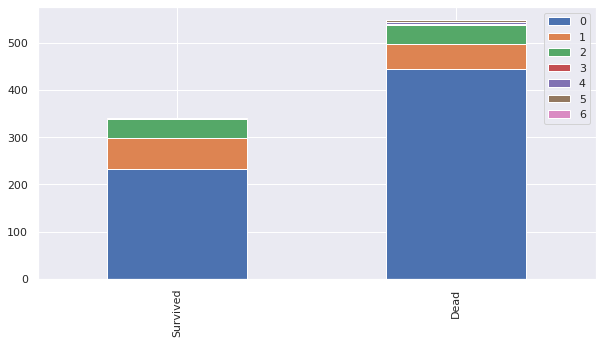
bar_chart('Embarked')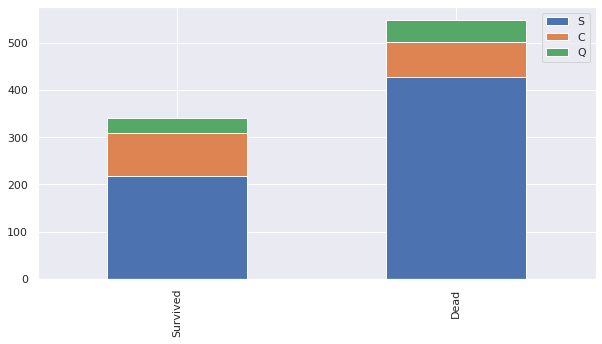
Feature engineering
Feature engineering은 데이터에 대한 도메인 지식을 바탕으로 feature을 기계가 학습하기 쉽게 바꾸는 작업을 말한다.
ex. 시간에 대해 학습할 때, 오후 2시 를 14:00으로 바꿀 수 있음
본 실습에서 feature engineering은 아래의 과정으로 진행된다.
1. feature를 유의미한 numerical vector로 나타내기
기계가 학습할 수 있도록 문자형, 범주형 데이터를 숫자로 바꿔준다.
- Name에서 유의미한 정보인 Mr, Miss, Mrs를 추출하여 숫자로 매핑
- Sex에서 'male', 'female'을 각각 0, 1로 매핑
- Age의 이산형 변수가 유의미하도록 binning
- 선착장 정보 'S', 'Q', 'C'를 각각 0, 1, 2로 매핑
- 객실 번호에서 가장 앞 알파벳을 숫자로 매핑
- SibSp(형제나 베우자)와 Parch(부모나 자식)을 묶어 FamilySize 피쳐로 나타내기
2. null data를 보정
- Age의 NaN 데이터를 Title의 중간값으로 보정
ex. Title이 Miss인 사람의 나이가 null이면, Miss의 나이 중간값 대입 - Fare의 null 데이터를 각 좌석의 중간값으로 보정
ex. 1등석의 요금이 null이면, 1등석 요금의 중간값 대입
3. 필요 없는 feature 제거
👉 Feature Engineering을 적용하여 필요한 데이터를 숫자로만 나타낼 수 있다.
❕ Feature Engineering 이전
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S |
❕ Feature Engineering 이후
| Survived | Pclass | Sex | Age | Fare | Cabin | Embarked | Title | FamilySize |
| 0 | 3 | 0 | 1 | 0 | 2.0 | 0 | 0 | 0.4 |
| 1 | 1 | 1 | 3 | 2 | 0.8 | 1 | 2 | 0.4 |
| 1 | 3 | 1 | 1 | 0 | 2.0 | 0 | 1 | 0.0 |
| 1 | 1 | 1 | 2 | 2 | 0.8 | 0 | 2 | 0.4 |
| 0 | 3 | 0 | 2 | 0 | 2.0 | 0 | 0 | 0.0 |
자세한 과정은 깃허브에 정리해두었습니다. (깃허브 바로가기)
Modeling
여러 모델을 이용해 데이터를 학습하고, 교차검증 점수로 모델의 성능을 평가해보자.
사용하는 모델 : KNN, DecisionTree, RandomForest, Naive Bayes, GradientBoosting, XGB, LightGBM, CatBoosting, Ensenble
(본 실습에서는 교차검증의 개념, 모델의 원리는 다루지 않습니다.)
# 교차 검증에 필요한 라이브러리 임포트
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
k_fold = KFold(n_splits=10, shuffle=True, random_state=0)
# 분류기 모델 임포트
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
❕ KNN
clf = KNeighborsClassifier(n_neighbors = 13)
scoring = 'accuracy'
score1 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score1)*100, 2)82.04
clf = DecisionTreeClassifier()
score2 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score2)*100, 2)80.02
❕ Random Forest
clf = RandomForestClassifier(n_estimators=13)
score3 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score3)*100, 2)81.59❕ Naive Bayes
clf = GaussianNB()
score4 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score4)*100, 2)78.56
❕ Gradient Boost
clf = GradientBoostingClassifier(n_estimators = 100)
score5 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score5)*100, 2)83.16
❕ XGBoost
clf = XGBClassifier()
score6 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score6)*100, 2)
83.5
❕ Light GBM
Colab에서 Light GBM 설치 방법 : https://url.kr/nkq8fo
from lightgbm import LGBMClassifier
clf = LGBMClassifier()
score7 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score7)*100, 2)
82.94
❕ Cat Boost
Colab에서 Cat Boost 설치 방법 : https://url.kr/1gwrtm
from catboost import CatBoostClassifier
clf = CatBoostClassifier(silent=True)
score8 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score8)*100, 2)
82.83❕ 앙상블 학습
KNN, Random Forest, Cat Boost로 앙상블 학습을 해보자.
from sklearn.ensemble import VotingClassifier
# 개별 모델 생성
knn = KNeighborsClassifier(n_neighbors = 13)
rf = RandomForestClassifier(n_estimators=13)
cb = CatBoostClassifier(silent=True)
voting_model = VotingClassifier(
estimators=[('knn',knn),('rf',rf),('cb',cb)],
voting='soft'
)
score10 = cross_val_score(clf, train_data, target, cv=k_fold, n_jobs=1, scoring=scoring)
round(np.mean(score10)*100, 2)
83.5
Submission
교차 검증의 점수가 가장 좋았던 XGB 모델로 제출 파일을 만들어보자.
clf = XGBClassifier() # 모델 생성
clf.fit(train_data, target) # 모델 학습
test_data = test.drop("PassengerId", axis=1).copy() # PassengerId 없는 데이이터 얕은 복사
prediction = clf.predict(test_data)
캐글에서 요구한 형식에 맞게 예측값과 PassengerId로 Data frame을 만들고, csv 파일로 변환한다.
submission = pd.DataFrame({
"PassengerId": test["PassengerId"],
"Survived": prediction
})
submission.to_csv('submission.csv', index=False)
결과!!
13000명 중 11187 등으로 상위 80%라는 처참한 성적을 받았다😥
타이타닉 예제만 따로 연구할 정도로 데이터셋이 널리 알려져 있어서 낮은 성적을 받아도 실망하지 말라는 조언을 들었지만..!
그래도 뭔가 슬펐다😓
계속 모델에 대해 배우며 좀 더 정확도를 높일 방법을 찾아갈 계획이다!!🔥
소스코드 : Pytorch/titanic_solution.ipynb at main · nayonsoso/Pytorch (github.com)
참고 강의 : https://youtu.be/aqp_9HV58Ls (강추!!)
GitHub - nayonsoso/Pytorch
Contribute to nayonsoso/Pytorch development by creating an account on GitHub.
github.com
'ML' 카테고리의 다른 글
| [ML] 교차 검증 (0) | 2022.02.20 |
|---|---|
| [ML] Fashion MNIST (0) | 2022.02.13 |
| [ML] CNN (0) | 2022.01.23 |
| [ML] 소프트맥스 회귀 (Softmax Regression) (1) | 2022.01.09 |
| [ML] 특성 공학과 규제 (1) | 2021.11.05 |


