※ 본 글은 한경훈 교수님의 머신러닝 강의를 정리, 보충한 글입니다. ※
[딥러닝I] 9강. 경사하강법 - YouTube
지난 강의 복습
손실함수는 '예측값과 실제값의 차이를 수치화'하는 함수이다.
손실함수는 패널티로 작용되며, 손실함수가 작을수록 인공지능의 성능은 좋아진다.
따라서 모델이 학습을 하는 과정은 손실함수 값을 최소화하기 위한 과정이라고도 할 수 있다.
손실함수로는 평균 제곱오차 MSE 와 교차엔트로피가 있다. (이 책에서는 교차엔트로피만 사용함)
이런 손실함수도 결국에는 '함수' 이므로 당연히 변수를 갖는다.
그렇다면 이 손실'함수'의 변수는 무엇일까?
손실함수의 변수
가중치와 편향이 손실함수의 변수이고, 입력 데이터는 손실함수의 계수이다.
cf. 함수에서 변수는 변할 수 있는 수이고, 계수는 변하지 않는 수이다.
ex. f(x) = ax + b 이면 a와 b는 계수, x는 변수
'입력되는 값'이라는 이미지 때문에 손실함수의 변수를 데이터로 착각하기 쉽지만,
입력된 데이터는 우리가 변화시킬 수 없으므로, 가중치와 편향을 조절하여 손실함수의 값을 줄여야 한다.
따라서 머신러닝의 과정은 가중치와 편향을 조절하여 손실함수(loss)를 줄여나가는 과정이라 할 수 있다.

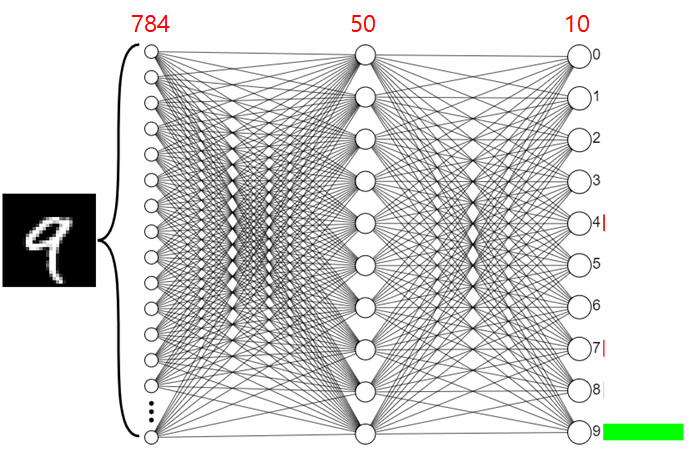
ex. 라벨이 (0,0,1)일때 왼쪽 신경망에 Affine, Softmax, Loss function을 적용해보자.
Affine : (a1, a2, a3)
= (x1w11 + x2w21 + b1, x1w12 + x2w22 + b2, x1w13 + x2w23 + b3)
Softmax : exp(a1)/exp(a1)+exp(a2)+exp(a3) , exp(a2)/exp(a1)+exp(a2)+exp(a3) , exp(a3)/exp(a1)+exp(a2)+exp(a3)
Loss function (cross entropy) : -Σ(0,0,1)log(softmax 값)
= - log(exp(a3)/exp(a1)+exp(a2)+exp(a3))

위 손실함수 값이 작을수록 잘 훈련된 모델이다.
이때 데이터의 값 x는 바꿀 수 없으므로 이 신경망의 손실함수에서
가중치와 편향인 w11, w12, w13, w21, w22, w23와 b1, b2, b3가 변수임을 다시 한번 확인할 수 있다.
손실함수의 변수 개수
각 층에 784, 50, 10개의 유닛이 있는 신경망의 경우
w 는 이전 유닛과 이후 유닛을 모두 연결해야 하고(=이전 유닛*이후 유닛), b는 이후 유닛만큼 있으면 되므로
손실함수 변수의 개수는 총 784×50+50+50×10+10=39,760 개이다.
추후 모델을 학습시킬 때 model.summary() 의 출력 중 [ Total params : ] 부분에서 손실함수에서 사용된 변수(가중치 + 편향)의 개수를 알 수 있다.
경사하강법(GD - gradient descent)
등장 배경
앞에서 말했다싶이, 머신러닝은 손실함수의 값을 최소화시키는 가중치와 편향을 구하는 과정이다.
수학에서 최소를 구할 때, 가장 일반적인 방법은 n변수 함수를 각각의 변수로 미분하여 n개의 방정식을 푸는 방법이다.
하지만 이 모델에서 우리가 구해야 하는 변수의 개수는 39,760개이므로 최소 39,760개의 미분 방정식을 풀어야 한다.
또한 이런 계산을 n번 반복해야 모델이 '학습'을 할 수 있으므로 모델을 학습시키기 위해서는 굉장히 많은 계산을 해야한다.
이는 매우 비효율적이므로, 머신러닝에서는 손실함수의 함수값이 최소값이 되게하는 변수를 구하기 위해 또 다른 방법을 사용한다.
경사하강법이란?
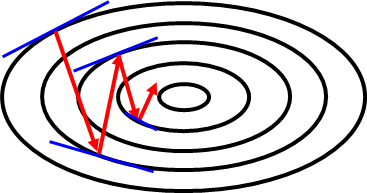
경사하강법을 비유하자면, 최단시간에 눈을 감고 산을 내려가는 것과 비슷하다.
눈을 감고 최단시간에 산을 내려가기 위해서는 현 위치에서 내려가는 경사가 가장 심한 쪽을 찾고,
한 바자국 이동하고, 다시 그 위치에서 경사가 가장 심한 쪽을 찾고, 이동하고,.. 하는 과정을 반복하면 된다.
이를 수학적으로 나타내보자.
앞서 우리는 방향미분 값이 최소가 되는 방향 즉, 함수값이 가장 빨리 감소하는 방향은 gradient의 반대 방향이라는 것을 배웠다.
따라서 변수를 gradient 반대방향으로 이동시키며 이를 계속 갱신시키면 된다.

경사하강법의 문제점 1 - 이동폭
이동 폭이 너무 크면 무질서하게 움직이고, 이동 폭이 너무 작으면 목적지까지 여러번 움직여야 한다는 문제점이 발생한다.

경사하강법의 문제점 2 - 극소점, 안장점
앞서 말했듯이 경사하강법은 산을 '눈감고' 내려가는 것과 비슷하다.
39,760개의 변수를 갖는 함수는 39,760 차원에 그려질텐데, 우리는 이 모양을 상상할 수 없기 때문이다.
따라서 변수의 보정폭이 적은 ( = gradient가 0에 가까운 ) 부분이 최소점인지, 극소점인지, 안장점인지 알 수 없다.
그저 gradient가 작은 쪽으로 향하다보면 최소점이 아닌 다른 점에 안착할 수 있다는 문제점이 있다.
경사하강법의 문제점 3 - 시간
손실함수의 값을 구하기 위해선, 하나의 데이터를 손실함수에 대입해야 한다.
하지만 모델을 학습시킬 때는 하나의 데이터가 아닌 '데이터셋'을 입력해야 한다.
경사하강법을 그대로 적용한다면 데이터셋의 크기만큼 변수 업데이트를 실행해야 하는데, 이는 굉장히 비효율적이다.
예를들어, MNIST의 경우 데이터셋에 6만개의 테스트 데이터가 담겨있다.
한번 변수를 업데이트 할 때마다 6만개의 데이터를 다 대입해야 하는데, 미분을 통해 업데이트까지 반복해야하므로, 실행에 굉장히 오래 걸린다.
이 문제를 해결하기 위해 Stochastic Gradient Descent(SGD) 방법을 사용한다.
경사하강법의 문제점 4 - 등위면과 gradient는 수직
앞서 배운 것 처럼 gradient와 등위면(선)은 항상 수직이다.
따라서 gradient의 반대 방향으로 움직인다는 것은 곧 등위면(선)과 수직으로 움직인다는 것을 의미한다.
등위면에 수직으로 움직이게 되면 목적 지점까지 지그재그로 진동하며 움직이게 되는데 이러한 과정은 매우 비효율적이다.
Stochastic Gradient Descent
한번의 최적화에 전체 데이터셋을 넣는 경사하강법과 달리 SGD는 적은 양의 데이터를 나누어 입력한다. (mini batch)
전체 데이터를 입력하는게 아니므로 정확도는 떨어지지만, 한번 시행에 걸리는 시간은 줄어든다.
결과적으로, 빨라진 시간을 이용해 여러번 최적화 할 수 있으므로 더 효율적으로 오차를 줄일 수 있다.

Optimizer
머신러닝에서 오차가 줄어들도록 변수를 최적화하는 방법을 옵티마이저라고 한다.
'시간이 오래 걸린다'는 경사하강법의 문제를 해결하기 위해 SGD가 나온 것 처럼,
경사하강법의 원리를 바탕으로하여 훨씬 개선된 옵티마이저들이 개발되어왔다.
아래 옵티마이저들의 모든 원리를 다룰순 없지만, 모두 손실함수의 변수인 가중치와 편차를 최적화하기 위해 사용된다는 점은 기억해두자!!
경사하강법 구현

# coding: utf-8
import numpy as np
import matplotlib.pylab as plt
from gradient_2d import numerical_gradient # numerical_gradient는 수치미분함수.
# cf. 수치미분으로 구해지는 gradient를 수치gradinet라 함
# f는 함수, init_x는 시작점, lr은 learning rate, step_num은 총 몇 발자국 갈건지
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
x_history = []
for i in range(step_num):
# x의 값을 기록
x_history.append( x.copy() ) # x.copy로 얕은복사 하므로 x와 연관없어짐
# 함수값(오차)이 최소가 되는 방향으로 x 업데이트
grad = numerical_gradient(f, x)
x -= lr * grad
return x, np.array(x_history)
def function_2(x):
return x[0]**2 + x[1]**2 # x**2 + y**2 와 같은 의미
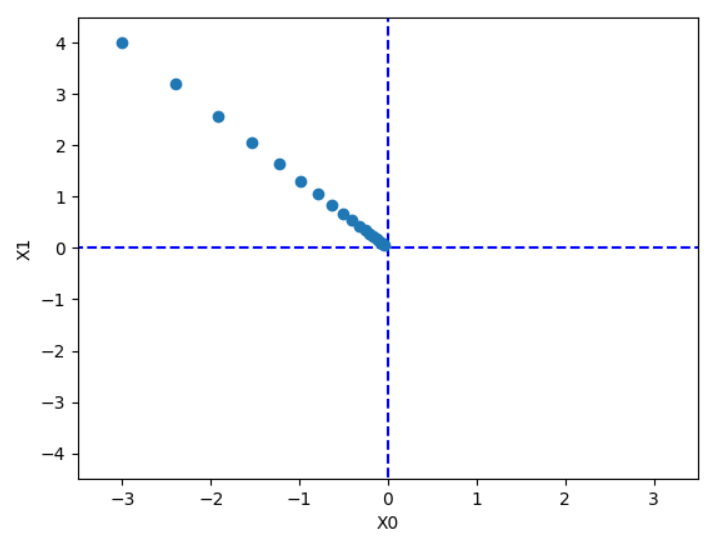
init_x = np.array([-3.0, 4.0])
lr = 0.1
step_num = 20
x, x_history = gradient_descent(function_2, init_x, lr=lr, step_num=step_num)
plt.plot( [-5, 5], [0,0], '--b')
plt.plot( [0,0], [-5, 5], '--b')
plt.plot(x_history[:,0], x_history[:,1], 'o') # [:,0] 은 전체 행에서 0번째 행 즉, x 좌표를 의미함
plt.xlim(-3.5, 3.5)
plt.ylim(-4.5, 4.5)
plt.xlabel("X0")
plt.ylabel("X1")
plt.show()
gradient_descent(function_2, init_x, lr=0.1, step_num=20) 의 결과
learning rate을 너무 크게 설정했을 때 (lr = 1.01)
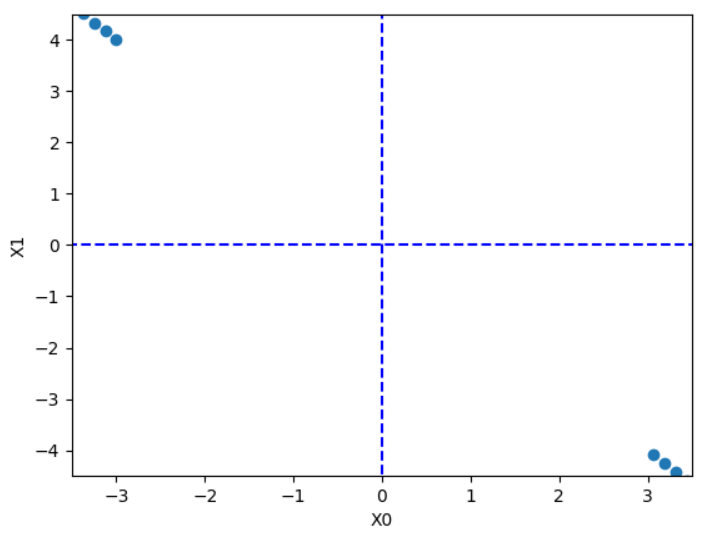
learning rate을 너무 작게 설정했을 때 (lr = 0.01)

경사하강법 적용
# coding: utf-8
import numpy as np
# 입력층과 출력층만 있는 간단한 네트워크
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 정규분포에서 (2,3) 행렬 랜덤 추출
# cf. np.random.rand()는 0-1사이에서 랜덤추출
def affine(self, x):
return np.dot(x, self.W) # 입력 x와 w를 곱함 -> affine 연산
# cf. affine 연산에 대한 오해를 풀어야겠음!
def loss(self, x, t):
z = self.affine(x) # (1,2)와 (2,3)행렬이 곱해졌으므로 (1,3)행렬 즉, 3차원 벡터 반환됨
y = softmax(z) # 벡터의 원소가 각각의 라벨일 확률을 나타낼 수 있도록 확률벡터로 변환
loss = cross_entropy_error(y, t) # 손실함수로 오차 계산
return loss
x = np.array([0.6, 0.9])
t = np.array([0, 0, 1])
net = simpleNet()
f = lambda w: net.loss(x, t) # f는 손실함수
# 경사하강법을 적용하는 함수는 손실함수이고, 손실함수의 변수는 가중치이므로 아래와 같이 수치 gradient 계산
dW = numerical_gradient(f, net.W)
for i in range(5):
dW = numerical_gradient(f, net.W)
print("net.W :",net.W)
print("softmax(net.affine(x)) :",softmax(net.affine(x)))
print("net.loss(x,t) :",net.loss(x,t),"\n")
net.W -= dW'ML' 카테고리의 다른 글
| [ML] 딥러닝 1 - 11강 계산 그래프 (0) | 2021.08.29 |
|---|---|
| [ML] 딥러닝 1 - 10강 수치미분을 통한 학습 구현 (0) | 2021.08.22 |
| [ML] 딥러닝 1 - 8강 수치미분과 gradient (0) | 2021.07.29 |
| [ML] 딥러닝 1 - 7강 엔트로피 (0) | 2021.07.29 |
| [ML] 딥러닝 1 - 6강 손실함수 (0) | 2021.07.23 |



